Detecte quedas com validação multi-região antes de alertar
Checks de múltiplas regiões + validação por consenso + API monitoring avançado com assertions JSON. Menos falsos positivos, mais precisão.
Não alertamos com um único check. Validamos antes de alertar.
Não é só ping verde — nosso diferencial
Não é só uptime. É validação distribuída real.
Muitas ferramentas dizem que o host responde. O Status Inspector foi feito para quando isso já não é suficiente: APIs com 200 e payload de erro, latência que queima o suporte e uma arquitetura de execução desacoplada (hub + probes) que detecta a partir de qualquer nó ativo.
- Checks executados a partir de múltiplas regiões
- Validação por consenso antes de alertar
- Menos falsos positivos
- Maior precisão na detecção de quedas
Se você já testou um monitor clássico e ainda achou problemas na mão, encontrou a ferramenta certa.
HTTP real
Não só ping — validamos respostas reais
Menos falsos positivos
Validação de conteúdo e lógica
Detecte degradação
Não espere tudo cair
Alertas mais inteligentes
Arquitetura distribuída real
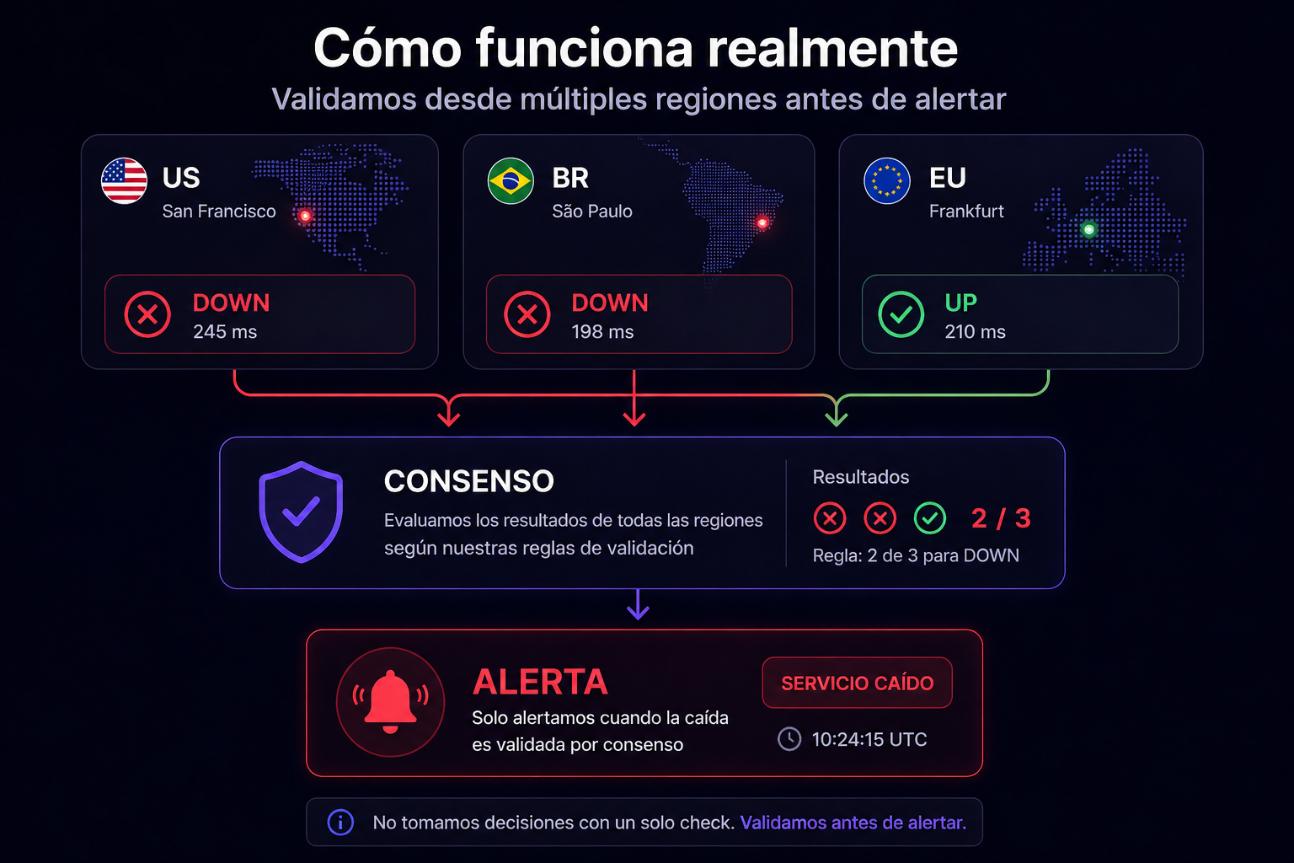
Como funciona de verdade
Monitoramento distribuído real com decisões baseadas em consenso.
Executamos checks de múltiplas regiões
Cada região reporta seu resultado
Aplicamos consenso para validar a queda
Só alertamos quando há certeza
Não tomamos decisões com um único ponto de falha.
6 formas de cobrir web, API e infra
Até 60 verificações/hora por serviço
4 funções: clareza para todo o time
6+ canais onde avisamos na hora
Monitoramento de uptime e APIs para empresas SaaS e times DevOps
Feito para equipes que não podem falhar
Um SaaS de monitoramento de sites pensado para equipes técnicas e produto: o mesmo painel para monitoramento de uptime e monitoramento de API, com alertas acionáveis e menos ruído.
SaaS
Evite churn por quedas: clientes percebem antes que a API ou o app deixem de cumprir o prometido.
DevOps
Alertas confiáveis e sem ruído: limites, degradação e incidentes claros para priorizar sem queimar o time.
Negócio
Proteja receita e reputação: visibilidade compartilhada com páginas de status e menos surpresas no suporte.
Usado por equipes que não podem falhar
+1,000
Monitores ativos
+50,000
Checks executados em múltiplas regiões
99.9%
Precisão de detecção graças à validação multi-região
Pare de descobrir tarde demais
Para equipes que dependem da web, das APIs e dos jobs em segundo plano. O custo não é só técnico: tempo de engenharia, tickets de suporte e confiança do cliente.
pain.validation_line
Cada minuto fora do ar é dinheiro perdido
Usuários frustrados, vendas perdidas e churn. O Status Inspector detecta problemas antes que escalem.
De múltiplos checks para uma única decisão confiável
Você define o que é «saudável»; nós verificamos continuamente e só avisamos quando há algo a corrigir.
Configure o monitor
Defina alvo, regras e limites de acordo com a criticidade.
Executamos checks distribuídos
Coletamos evidências de nós ativos em múltiplas regiões.
Validamos com consenso
Correlacionamos resultados e reduzimos falsos positivos antes de decidir.
Geramos um alerta confiável
Só notificamos quando há certeza operacional.
Uma visão da saúde real do que importa para você
Estado calculado com base em múltiplas regiões, não em um único check.
- • Painel único
- • Negócio + produto + ops
- • Uma única fonte da verdade
Sites
Quedas e lentidão em tempo real, com contexto em cada alerta.
APIs
Respostas, tempos, códigos e regras avançadas sobre o payload
Infraestrutura
DNS, portas TCP, SSL e ICMP quando aplicável
Heartbeat
Cron e jobs que precisam «avisar». Detecte falhas silenciosas de processos invisíveis
Mais recursos
SSL
Monitoramos certificados e avisamos com antecedência da expiração
Páginas de status
Páginas públicas para mostrar aos clientes a saúde dos seus serviços
Regras de alerta
UP, DEGRADED, DOWN e limites de falhas consecutivas — menos falsos positivos
REST API e automação
Automatize criação e consulta de monitores e incidentes a partir da sua stack
Equipes e funções
Convites, 4 funções de usuário e multi-conta.
Histórico
Relatórios de checks, alertas enviados e incidentes para retrospectiva.
Janelas de manutenção
Defina janelas de manutenção para silenciar alertas durante deploys, migrações ou tarefas programadas.
Integrações
Conecte com Zapier, Make, n8n ou sua própria stack via webhook. Automatize fluxos de incidentes sem código extra.
Grupos de monitores
Organize e filtre monitores por projeto, ambiente ou time. Uma visão da saúde de cada área do seu stack.
API Monitoring que valida o que realmente importa
Validamos respostas, não apenas códigos de status.
Não apenas verificamos respostas. Validamos comportamento.
✔ Assertions avançadas sobre JSON
✔ Validação de estrutura e conteúdo
✔ Regras personalizadas por endpoint
✔ Detecta erros mesmo com status 200
✔ Monitoramento real da lógica de negócio
{
"status": "ok",
"data": {
"users": []
}
}Você esperava users > 0 -> ERRO DETECTADO
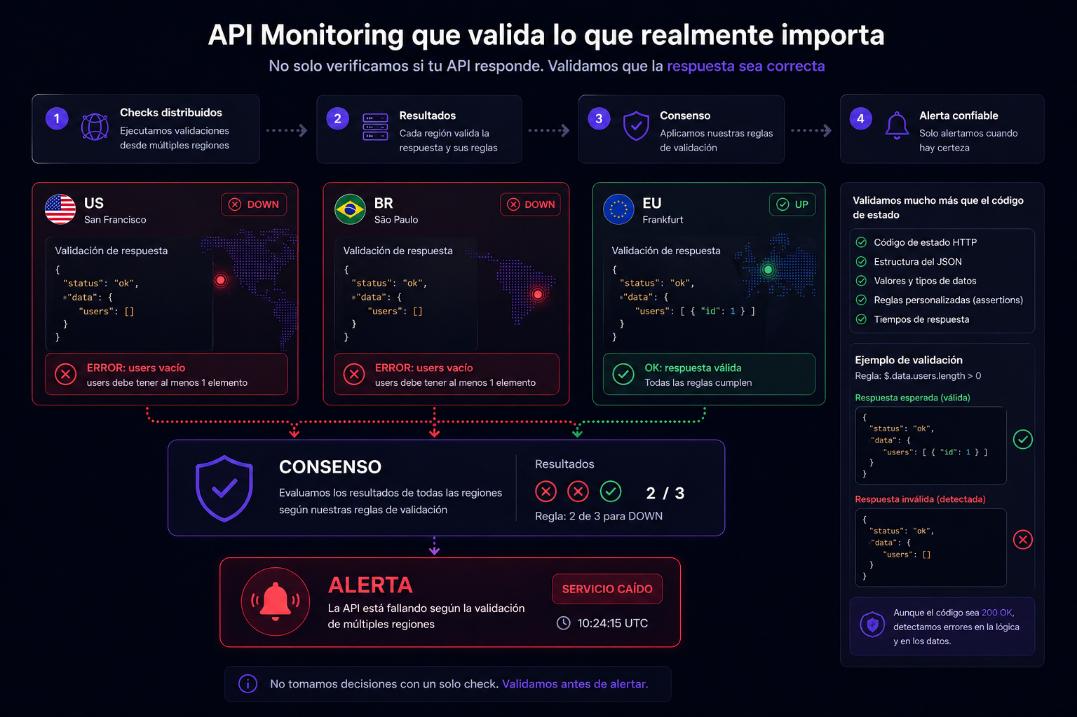
Um endpoint pode responder 200 e estar quebrado. Nós detectamos.
Por que Status Inspector em vez de um monitor «só ping»?
Muitas ferramentas dizem «está no ar». Nós ajudamos a saber se o serviço entrega o que seus usuários precisam: corpo da API, latência, certificados e falsos positivos sob controle — para priorizar bem quando algo dá errado.
Ping vs funcionamento real
Ping só verifica se responde; Status Inspector valida se realmente funciona.
Validação multi-região
Checks distribuídos para confirmar o estado real do serviço.
Consenso antes de alertar
Não alertamos por falha isolada quando a evidência não é conclusiva.
API monitoring avançado
Assertions JSON, regras por endpoint e menos ruído operacional.
Recursos
Base sólida para equipes que escalam
Monitoramento distribuído
Multi-região, validação por consenso e alta precisão.
API Monitoring
Assertions JSON, validação lógica e regras avançadas por endpoint.
Alertas confiáveis
Menos ruído e decisões baseadas em consenso.
Seguro por padrão
Validação rigorosa, OAuth e convites com expiração
Operação escalável
Arquitetura distribuída real com execução desacoplada (hub + probes).
Sistema de validação baseado em consenso multi-região
Correlaciona checks entre nós para decidir com maior certeza.
MTBF e MTTR
Métricas de confiabilidade no painel: tempo médio entre falhas e tempo médio de recuperação por serviço.
Seu painel responde perguntas. Agora também age.
Pergunte sobre o status dos seus serviços, consulte o último incidente ou silencie um monitor durante um deploy — tudo pelo chat integrado ao painel, sem menus ou buscas.
- "Quantos monitores estão fora agora?"
- "Coloque a API de pagamentos em manutenção"
- "Quanto durou o último incidente?"
- Respostas com dados reais da sua conta, em segundos.
Incluído em todos os planos. Sem configuração extra.
Comece grátis. Escale quando crescer.
Preços claros frente a concorrentes «só ping»: intervalos, API, assertions, Heartbeat e detecção multi-região com execução distribuída real.
Oferta de lançamento: Grátis e Pro sem custo nem cartão nesta fase. Quando a cobrança ativar, o Pro usará o preço indicativo do card.
Âncora de valor: menos que uma hora de engenharia reagindo tarde a um falso «tudo verde».
Inclui validação multi-região e API monitoring avançado conforme o plano.
Grátis
Valide o produto com seu time, sem cartão.
Plano gratuito sem limite de tempo e sem cartão.
Diferente de ofertas «só ping», aqui você valida se a API devolve o esperado — não só um 200.
- Até 20 monitores
- Intervalo mínimo entre checks: 5 minutos
- Até 10 canais de notificação
- Até 1 membros (convites pendentes contam no limite)
- Até 2 páginas de status públicas
- Até 2 grupos de monitores
- Até 50 regras de alerta
- API pública indisponível neste plano
Pro
A cadência de checks e a API que você espera em produção.
Mesmo stack de produção
Sem surpresas: limites reais listados abaixo.
Inclui validação multi-região e API monitoring avançado
- Até 200 monitores
- Intervalo mínimo entre checks: 1 minuto
- Até 50 canais de notificação
- Até 10 membros (convites pendentes contam no limite)
- Até 25 páginas de status públicas
- Até 20 grupos de monitores
- Até 300 regras de alerta
- API pública: até 120 requisições por minuto por token
- Assertions JSON avançadas em monitores HTTP/API
- Monitoramento Heartbeat para cron/jobs (check-in por token)
- Métricas MTBF e MTTR no painel (dashboard e detalhe do monitor)
- Assistente IA com dados reais da sua conta
Enterprise
Limites, SLA e integrações nos seus termos.
SLA, implantação e termos comerciais sob medida.
- Limites operacionais ampliados ou ilimitados por acordo
- SLA e termos comerciais personalizados
- Integrações, implantação e suporte dedicado
Comparativo de planos
Mesmo catálogo que você verá no painel após o cadastro. Sem letras miúdas escondidas: intervalos, API e recursos-chave lado a lado.
| Recurso | Grátis | Pro | Enterprise |
|---|---|---|---|
| Intervalo mínimo entre checks | 5 minutos | 1 minuto | 30 segundos |
| Monitores | 20 | 200 | Ilimitado |
| API pública (token Bearer) | Não | Sim (até 120 req/min) | Sim (até 300 req/min) |
| Assertions JSON (HTTP/API) | Não | Sim | Sim |
| Heartbeat (cron / jobs) | Não | Sim | Sim |
| Nós regionais máximos por check | 1 | 3 | 5 |
| Estado degradado (latência / qualidade) | Sim | Sim | Sim |
| Canais de alerta | 10 | 50 | Ilimitado |
| Membros do time | 1 | 10 | Ilimitado |
| Assistente IA integrado | Não | Sim | Sim |
Perguntas frequentes
- • Dúvidas comuns ao escolher monitoramento de uptime e APIs
Os planos são pagos?
Não. Nesta fase Gratuito e Pro estão sem custo. Não há gateway de pagamento nem pedido de cartão. O plano Enterprise (sob medida) é tratado por contato.
Onde recebo os alertas?
Por email, Slack, Discord, Google Chat, Telegram, Pushbullet ou webhook para uma URL sua (Zapier, Make ou stack própria). Cada canal é configurado uma vez e ligado às regras que você escolher.
Posso compartilhar o status com clientes?
Sim. As páginas públicas de status oferecem uma URL (tipo /p/seu-slug) para compartilhar. Mostra os monitores escolhidos, uptime recente e incidentes que você abre ou fecha no painel.
Posso convidar meu time na mesma conta?
Sim. Convide por email e atribua uma das quatro funções: Owner, Admin, Editor ou Viewer. Se a pessoa não tem conta, recebe link de cadastro; convites expiram em 7 dias se não forem aceitos.
Com que frequência rodam os checks?
Depende do plano e do monitor. No Grátis, o intervalo mínimo entre checks é 5 minutos; no Pro, 1 minuto; no Enterprise, a partir de 30 segundos.
Posso evitar alertas por falhas pontuais?
Sim. Em cada regra de alerta você define um limiar de falhas consecutivas. Por exemplo com limite 2: se o primeiro check falhar, não envia alerta; se o segundo também falhar, enviamos — reduz ruído por picos de latência ou reinícios breves.
O que acontece quando um monitor muda de estado?
Quando um serviço fica DOWN além do limite, geramos evento de alerta e notificamos os canais. Ao voltar UP, disparamos recuperação. Em manutenção, alertas de disponibilidade não são enviados.
Inclui ping ICMP e Heartbeat?
Sim para ping ICMP como outro tipo de monitor (mesma fila, incidentes e alertas que HTTP/TCP). Check-in de cron/jobs (Heartbeat) está nos planos que o catálogo incluir; o plano gratuito não permite criá-lo.
Posso usar API para gerir monitores?
Sim: /api/v1 com token Bearer, escopos e rate limit por plano. Documentação e limites batem com a tela «Plano e limites» do painel.
Como evita falsos positivos?
Aplicamos validação por consenso multi-região antes de disparar alertas críticas.
O que significa validação multi-região?
O estado não depende de um único check: correlacionamos evidências de múltiplas regiões ativas.
Como funciona o API monitoring?
Executamos checks HTTP/API, avaliamos tempos/status e validamos conteúdo com regras e assertions JSON.
O que posso validar com JSON assertions?
Estrutura, campos, valores e regras lógicas do payload para detectar falhas mesmo quando a API retorna 200.
O que acontece se atingir o limite do meu plano?
O sistema avisa antes de atingir o limite. Monitores e dados existentes nunca são apagados; você simplesmente não poderá criar novos recursos até mudar de plano ou remover os atuais.
Quando começa a cobrança do plano Pro?
O Pro está gratuito durante a fase de lançamento. Quando a cobrança for ativada, comunicaremos com antecedência. O preço indicativo está no card de preços. Você pode optar por continuar ou ficar no plano gratuito.
Posso cancelar ou mudar de plano a qualquer momento?
Sim. Sem contratos de fidelidade. Você pode fazer upgrade, downgrade ou cancelar pelo painel quando quiser. Os dados históricos são mantidos conforme a política de retenção do plano.
Monitoramento SaaS, ferramenta de uptime e serviço de monitoramento de API
O Status Inspector reúne monitoramento de sites, ferramenta de uptime e serviço de monitoramento de API em um painel: validação real (não só ping) para equipes SaaS, DevOps e equipes técnicas. Detecte quedas, erros e degradação antes do usuário final ou do negócio sentir.
Contato
Suporte, planos Enterprise ou integrações sob medida: fale conosco.
contacto@statusinspector.com
Horário
Segunda a sexta
9:00 - 18:00
- • Suporte técnico e dúvidas de produto
- • Acesso Enterprise e integrações
- • Resposta pelo formulário
Recupere minutos quando mais importam
Cada incidente detectado mais cedo é menos tempo no suporte, menos churn e mais confiança. Comece grátis e valide o fluxo com seu time.
Menos alertas falsas. Mais confiança em cada decisão.