Détectez les pannes avec validation multi-région avant d’alerter
Checks depuis plusieurs régions + validation par consensus + API monitoring avancé avec assertions JSON. Moins de faux positifs, plus de précision.
Nous n’alertons pas sur un seul check. Nous validons avant d’alerter.
Pas seulement un ping vert — notre différenciateur
Ce n’est pas seulement de l’uptime. C’est une validation distribuée réelle.
Beaucoup d’outils disent que l’hôte répond. Status Inspector est fait pour quand cela ne suffit plus : API en 200 avec corps d’erreur, latence qui fait exploser le support, et une architecture d’exécution découplée (hub + probes) qui détecte depuis n’importe quel nœud actif.
- Checks exécutés depuis plusieurs régions
- Validation par consensus avant alerte
- Moins de faux positifs
- Plus de précision dans la détection des pannes
Si vous avez essayé la supervision classique et que vous trouviez encore les problèmes à la main, vous avez trouvé le bon outil.
HTTP réel
Pas seulement du ping — nous validons les vraies réponses
Moins de faux positifs
Validation du contenu et de la logique
Repérez la dégradation
N’attendez pas que tout tombe
Alertes plus intelligentes
Architecture distribuée réelle
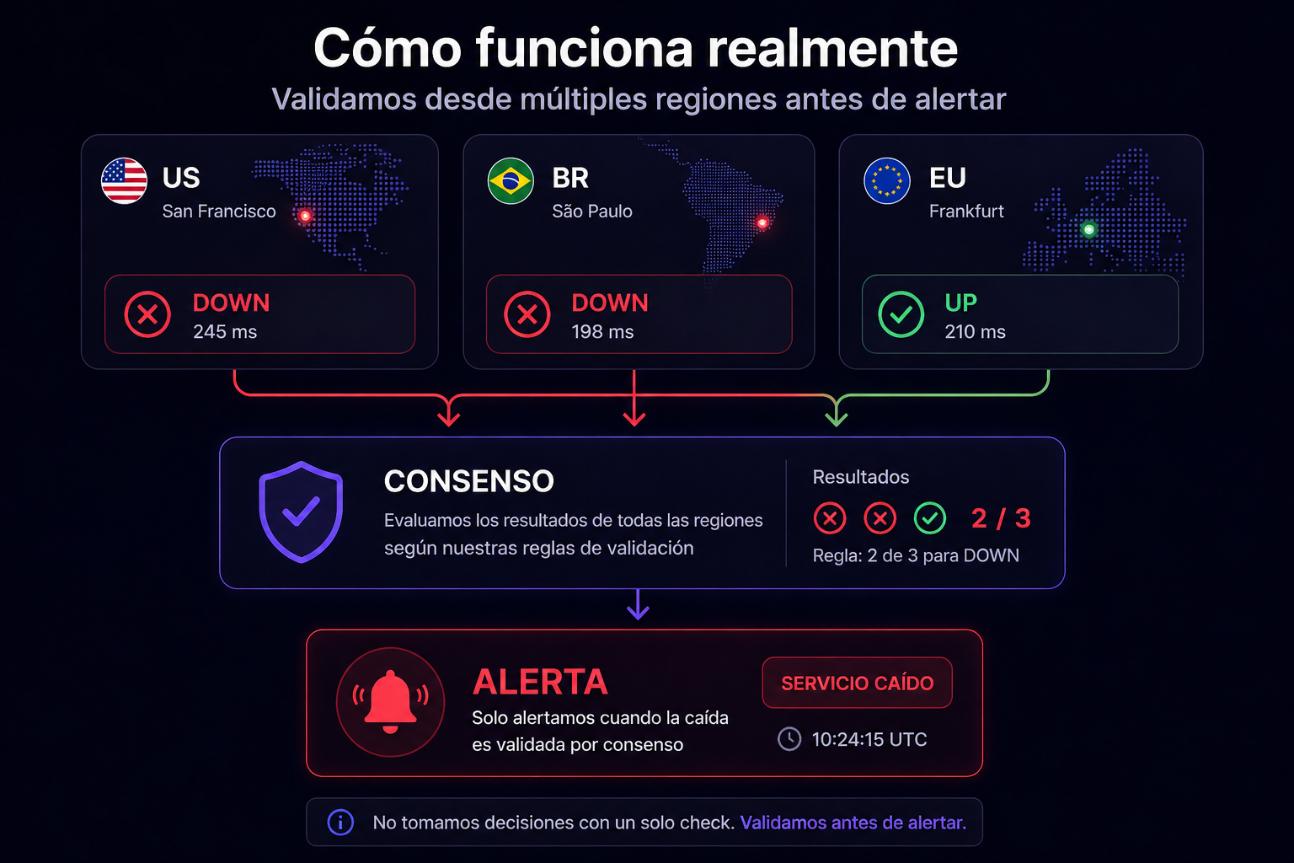
Comment cela fonctionne vraiment
Supervision distribuée réelle avec décisions basées sur le consensus.
Nous exécutons des checks depuis plusieurs régions
Chaque région remonte son résultat
Nous appliquons un consensus pour valider la panne
Nous alertons uniquement quand il y a certitude
Nous ne prenons pas de décisions avec un seul point de défaillance.
6 façons de couvrir web, API et infra
Jusqu’à 60 vérifications/heure par service
4 rôles : clarté pour toute l’équipe
6+ canaux où nous vous prévenons tout de suite
Supervision de disponibilité et d’API pour entreprises SaaS et équipes DevOps
Conçu pour les équipes qui ne peuvent pas se permettre d’échouer
Un SaaS de supervision de sites web pensé pour équipes techniques et les équipes produit : un même panneau pour suivi de disponibilité (uptime) et supervision d’API, avec des alertes actionnables et moins de bruit.
SaaS
Réduisez le churn lié aux pannes : vos clients remarquent souvent avant que l’API ou l’app cessent de tenir leurs promesses.
DevOps
Alertes fiables et peu bruyantes : seuils, dégradation et incidents clairs pour prioriser sans épuiser l’équipe.
Business
Protégez revenus et réputation : visibilité partagée avec pages de statut et moins de mauvaises surprises au support.
Utilisé par des équipes qui ne peuvent pas échouer
+1,000
Moniteurs actifs
+50,000
Checks exécutés dans plusieurs régions
99.9%
Précision de détection grâce à la validation multi-région
Arrêtez d’apprendre la nouvelle quand il est trop tard
Pour les équipes qui dépendent du web, des API et des tâches en arrière-plan. Le coût n’est pas seulement technique : temps d’ingénierie, tickets support et confiance client.
pain.validation_line
Chaque minute d’indisponibilité, c’est de l’argent perdu
Utilisateurs frustrés, ventes perdues et churn. Status Inspector détecte les problèmes avant qu’ils n’explosent.
De multiples checks à une seule décision fiable
Vous définissez ce que signifie « en bonne santé » ; nous vérifions en continu et ne vous dérangeons que lorsqu’il y a un vrai problème.
Vous configurez le moniteur
Définissez cible, règles et seuils selon la criticité.
Nous exécutons des checks distribués
Nous collectons des preuves depuis des nœuds actifs multi-région.
Nous validons par consensus
Nous corrélons les résultats et réduisons les faux positifs avant décision.
Nous générons une alerte fiable
Notification uniquement quand la certitude opérationnelle est atteinte.
Une seule vue de la santé réelle de ce qui vous importe
État calculé depuis plusieurs régions, pas depuis un seul check.
- • Panneau unique
- • Business + produit + ops
- • Une seule source de vérité
Sites web
Pannes et lenteur en temps réel, avec du contexte dans chaque alerte.
API
Réponses, temps, codes et règles avancées sur les charges utiles
Infrastructure
DNS, ports TCP, SSL et ICMP le cas échéant
Heartbeat
Cron et jobs qui doivent « signaler leur présence ». Détectez les échecs silencieux des processus invisibles
Plus de capacités
SSL
Nous surveillons les certificats et vous prévenons avant expiration
Pages de statut
Des pages publiques pour montrer à vos clients l’état de vos services
Règles d’alerte
UP, DEGRADED, DOWN et seuils d’échecs consécutifs — moins de faux positifs
API REST et automatisation
Automatisez la création et la consultation des moniteurs et incidents depuis votre stack
Équipes et rôles
Invitations, 4 rôles utilisateur et multi-compte.
Historique
Rapports de checks, alertes envoyées et incidents pour la rétrospective.
Fenêtres de maintenance
Définissez des fenêtres de maintenance pour silencer les alertes durant les déploiements, migrations ou tâches planifiées.
Intégrations
Connectez Zapier, Make, n8n ou votre stack via webhook. Automatisez les flux d'incidents sans code supplémentaire.
Groupes de moniteurs
Organisez et filtrez les moniteurs par projet, environnement ou équipe. Une vue de l'état de chaque zone de votre stack.
API Monitoring qui valide ce qui compte vraiment
Nous validons les réponses, pas seulement les codes de statut.
Nous ne vérifions pas seulement les réponses. Nous validons le comportement.
✔ Assertions JSON avancées
✔ Validation de structure et de contenu
✔ Règles personnalisées par endpoint
✔ Détecte les erreurs même avec un status 200
✔ Supervision réelle de la logique métier
{
"status": "ok",
"data": {
"users": []
}
}Vous attendiez users > 0 -> ERREUR DÉTECTÉE
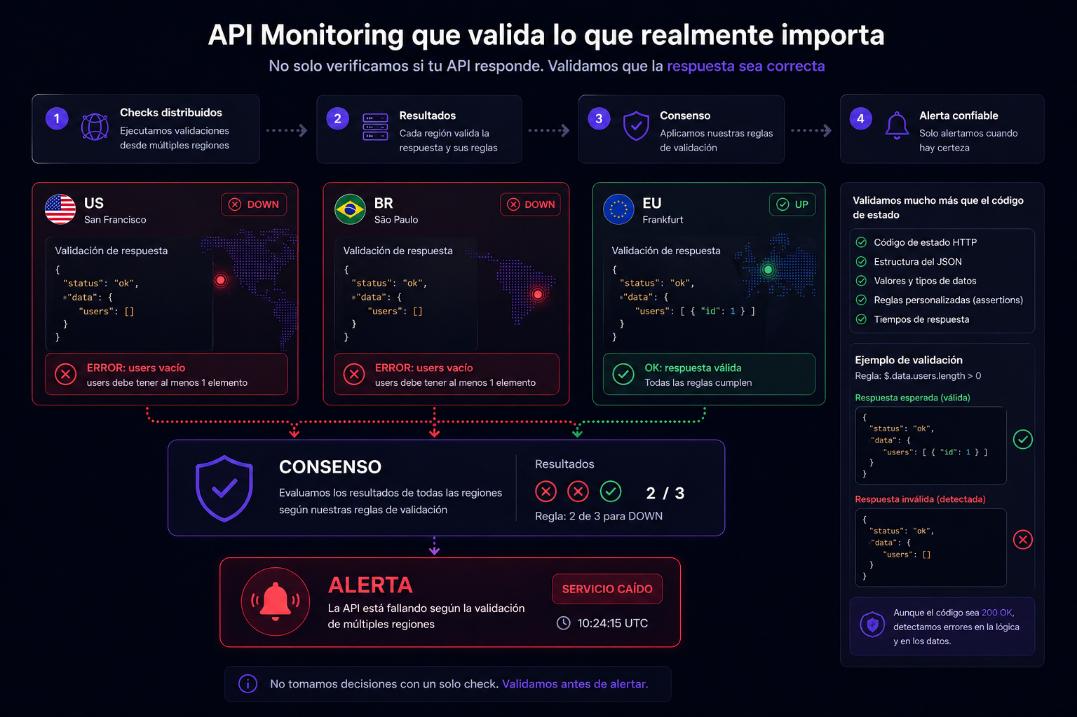
Un endpoint peut répondre 200 et être cassé. Nous le détectons.
Pourquoi Status Inspector plutôt qu’un moniteur « ping only » ?
Beaucoup d’outils disent « c’est up ». Nous aidons à savoir si le service répond aux besoins réels de vos utilisateurs : corps d’API, latence, certificats et faux positifs maîtrisés — pour bien prioriser quand ça coince.
Ping vs fonctionnement réel
Ping vérifie seulement la réponse ; Status Inspector valide le vrai fonctionnement.
Validation multi-région
Des checks distribués confirment l’état réel du service.
Consensus avant alerte
Aucune alerte sur un échec isolé quand les preuves sont insuffisantes.
API monitoring avancé
Assertions JSON, règles par endpoint et moins de bruit opérationnel.
Fonctionnalités
Une base solide pour les équipes qui montent en charge
Supervision distribuée
Multi-région, validation par consensus et haute précision.
API Monitoring
Assertions JSON, validation logique et règles avancées par endpoint.
Alertes fiables
Moins de bruit et décisions basées sur le consensus.
Sécurité par défaut
Validation stricte, OAuth et invitations avec expiration
Opérations scalables
Architecture distribuée réelle avec exécution découplée (hub + probes).
Système de validation basé sur un consensus multi-région
Corrèle les checks entre nœuds pour décider avec plus de certitude.
MTBF et MTTR
Métriques de fiabilité dans le tableau de bord : temps moyen entre pannes et temps moyen de rétablissement par service.
Votre tableau de bord répond aux questions. Il agit aussi désormais.
Demandez l'état de vos services, consultez le dernier incident ou mettez un moniteur en maintenance pendant un déploiement — tout depuis le chat intégré au panel, sans menus ni recherches.
- "Combien de moniteurs sont en panne maintenant ?"
- "Mets l'API de paiement en maintenance"
- "Combien de temps a duré le dernier incident ?"
- Réponses avec les données réelles de votre compte, en quelques secondes.
Inclus dans tous les plans. Aucune configuration supplémentaire.
Commencez gratuitement. Montez en charge quand vous grandissez.
Tarifs clairs face aux concurrents « ping only » : intervalles, API, assertions, Heartbeat et détection multi-région sur une exécution distribuée réelle.
Offre de lancement : Gratuit et Pro sans frais ni carte pendant cette phase. Quand la facturation sera active, Pro utilisera le prix indicatif affiché sur la carte.
Ancre de valeur : moins qu’une heure d’ingénierie qui réagit tard à un faux « tout vert ».
Inclut la validation multi-région et un API monitoring avancé selon l’offre.
Gratuit
Validez le produit avec votre équipe, sans carte.
Offre gratuite sans limite de durée et sans carte.
Contrairement aux offres « ping only », ici vous validez que l’API renvoie ce qu’il faut — pas seulement un 200.
- Jusqu’à 20 moniteurs
- Intervalle minimum entre les checks : 5 minutes
- Jusqu’à 10 canaux de notification
- Jusqu’à 1 membres (invitations en attente incluses dans la limite)
- Jusqu’à 2 pages de statut publiques
- Jusqu’à 2 groupes de moniteurs
- Jusqu’à 50 règles d’alerte
- API publique non disponible sur cette offre
Pro
La cadence de checks et l’API que vous attendez en production.
Même stack qu’en production
Pas de surprise : limites réelles listées ci-dessous.
Inclut la validation multi-région et un API monitoring avancé
- Jusqu’à 200 moniteurs
- Intervalle minimum entre les checks : 1 minute
- Jusqu’à 50 canaux de notification
- Jusqu’à 10 membres (invitations en attente incluses dans la limite)
- Jusqu’à 25 pages de statut publiques
- Jusqu’à 20 groupes de moniteurs
- Jusqu’à 300 règles d’alerte
- API publique : jusqu’à 120 requêtes par minute par jeton
- Assertions JSON avancées sur les moniteurs HTTP/API
- Supervision Heartbeat pour cron/jobs (check-in par jeton)
- Indicateurs MTBF et MTTR dans le panneau (tableau de bord et détail moniteur)
- Assistant IA avec données réelles de votre compte
Enterprise
Limites, SLA et intégrations selon vos conditions.
SLA, déploiement et conditions commerciales sur mesure.
- Limites opérationnelles élargies ou illimitées selon accord
- SLA et conditions commerciales adaptées
- Intégrations, déploiement et support dédié
Comparaison des offres
Même catalogue qu’après inscription dans le panneau. Pas de petites lignes cachées : intervalles, API et fonctions clés côte à côte.
| Fonctionnalité | Gratuit | Pro | Enterprise |
|---|---|---|---|
| Intervalle minimum entre les checks | 5 minutes | 1 minute | 30 secondes |
| Moniteurs | 20 | 200 | Illimité |
| API publique (jeton Bearer) | Non | Oui (jusqu’à 120 req/min) | Oui (jusqu’à 300 req/min) |
| Assertions JSON (HTTP/API) | Non | Oui | Oui |
| Heartbeat (cron / jobs) | Non | Oui | Oui |
| Nœuds régionaux max par check | 1 | 3 | 5 |
| État dégradé (latence / qualité) | Oui | Oui | Oui |
| Canaux d’alerte | 10 | 50 | Illimité |
| Membres d’équipe | 1 | 10 | Illimité |
| Assistant IA intégré | Non | Oui | Oui |
Questions fréquentes
- • Questions typiques pour choisir une supervision d’uptime et d’API
Les offres sont-elles payantes ?
Non. Pour l’instant Gratuit et Pro sont sans frais. Pas de passerelle de paiement ni de carte bancaire. L’offre Enterprise (sur mesure) se gère par contact.
Où puis-je recevoir les alertes ?
Email, Slack, Discord, Google Chat, Telegram, Pushbullet ou webhook vers une URL que vous fournissez (Zapier, Make ou votre stack). Chaque canal se configure une fois puis se lie aux règles choisies.
Puis-je partager l’état avec mes clients ?
Oui. Les pages de statut publiques donnent une URL (du type /p/votre-slug) à partager. On y voit les moniteurs choisis, l’uptime récent et les incidents ouverts ou fermés depuis le panneau.
Puis-je inviter mon équipe sur le même compte ?
Oui. Invitez par email et attribuez l’un des quatre rôles : Owner, Admin, Editor ou Viewer. Sans compte, la personne reçoit un lien d’inscription ; les invitations expirent après 7 jours si non acceptées.
À quelle fréquence les checks s’exécutent-ils ?
Cela dépend de l’offre et du moniteur. Sur Gratuit, l’intervalle minimum entre checks est 5 minutes ; sur Pro, 1 minute ; sur Enterprise, à partir de 30 secondes.
Puis-je éviter les alertes pour des échecs ponctuels ?
Oui. Chaque règle d’alerte peut définir un seuil d’échecs consécutifs. Par exemple avec seuil 2 : le premier échec n’envoie pas d’alerte ; si le second échoue aussi, nous notifions — moins de bruit pour pics de latence ou redémarrages brefs.
Que se passe-t-il quand un moniteur change d’état ?
Quand un service passe DOWN au-delà du seuil, nous créons un événement d’alerte et notifions les canaux. Au retour UP, un événement de récupération. En maintenance, pas d’alertes de disponibilité.
Inclut-il le ping ICMP et Heartbeat ?
Oui pour le ping ICMP comme autre type de moniteur (même file d’exécution, incidents et alertes qu’HTTP/TCP). Les check-ins cron/jobs (Heartbeat) sont disponibles sur les offres du catalogue qui les incluent ; l’offre gratuite ne permet pas leur création.
Puis-je utiliser une API pour gérer les moniteurs ?
Oui : /api/v1 avec jeton Bearer, scopes et limite de débit par offre. Documentation et limites alignées sur l’écran « Offre et limites » du panneau.
Comment évitez-vous les faux positifs ?
Nous appliquons une validation par consensus multi-région avant de déclencher les alertes critiques.
Que signifie la validation multi-région ?
L’état ne dépend pas d’un seul check : nous corrélons des preuves depuis plusieurs régions actives.
Comment fonctionne l’API monitoring ?
Nous exécutons des checks HTTP/API, évaluons temps/codes et validons le contenu avec des règles et des assertions JSON.
Que puis-je valider avec les assertions JSON ?
Structure, champs, valeurs et règles logiques du payload pour détecter des pannes même avec un status 200.
Que se passe-t-il si j'atteins la limite de mon offre ?
Le système vous prévient avant d'atteindre la limite. Les moniteurs et données existants ne sont jamais supprimés ; vous ne pouvez simplement plus créer de nouvelles ressources tant que vous n'avez pas changé d'offre ou supprimé des ressources.
Quand la facturation de Pro commence-t-elle ?
Pro est gratuit pendant la phase de lancement actuelle. Quand la facturation sera activée, nous vous en informerons à l'avance. Le prix indicatif est affiché sur la carte. Vous pourrez choisir de passer à Pro ou de rester sur l'offre gratuite.
Puis-je annuler ou changer d'offre à tout moment ?
Oui. Pas de contrat d'engagement. Vous pouvez passer à une offre supérieure ou inférieure, ou annuler depuis le panneau quand vous le souhaitez. Les données historiques sont conservées selon la politique de rétention de votre offre.
Supervision SaaS de sites, outil d’uptime et service de supervision d’API
Status Inspector réunit supervision de sites web, outil de surveillance de disponibilité et service de supervision d’API dans un seul panneau : validation réelle (pas seulement du ping) pour équipes SaaS, DevOps et équipes techniques. Détectez pannes, erreurs et dégradation avant les utilisateurs finaux ou le business.
Contact
Support, offres Enterprise ou intégrations sur mesure : écrivez-nous.
contacto@statusinspector.com
Horaires
Lundi au vendredi
9:00 - 18:00
- • Support technique et questions produit
- • Accès Enterprise et intégrations
- • Réponse via formulaire
Gagnez des minutes quand elles comptent le plus
Chaque incident détecté plus tôt, c’est moins de temps au support, moins de churn et plus de confiance. Commencez gratuitement et validez le flux avec votre équipe.
Moins de fausses alertes. Plus de confiance dans chaque décision.